Llama 3.2 Vision
2024年11月6日
Llama 3.2 Vision 现在可以在 Ollama 中运行,提供 11B 和 90B 两种尺寸。
开始使用
下载 Ollama 0.4,然后运行
ollama run llama3.2-vision
要运行更大的 90B 模型
ollama run llama3.2-vision:90b
要将图像添加到提示中,请将其拖放到终端中,或者在 Linux 上将图像路径添加到提示中。
注意:Llama 3.2 Vision 11B 至少需要 8GB 的 VRAM,而 90B 模型至少需要 64 GB 的 VRAM。
示例
手写
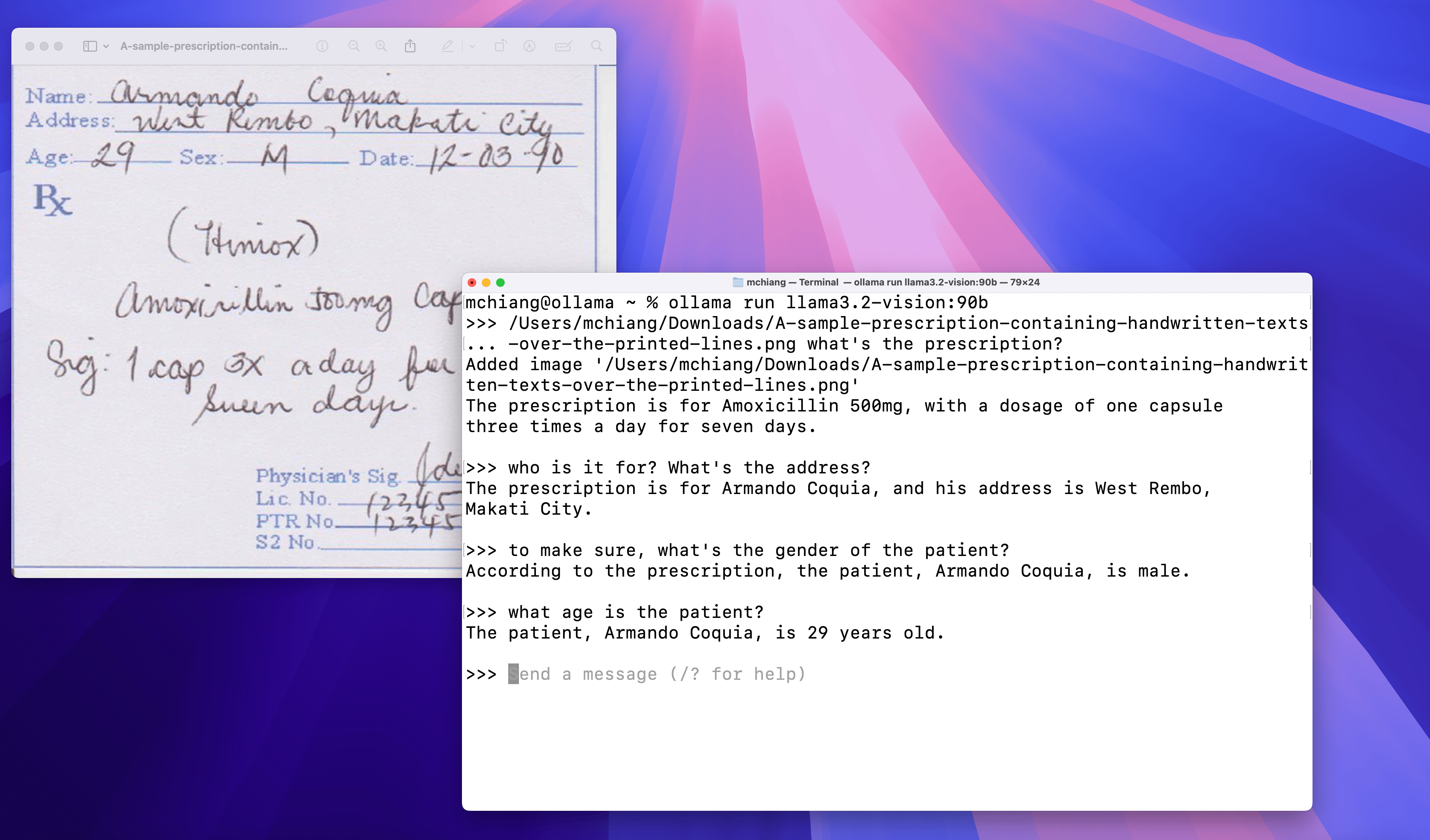
光学字符识别 (OCR)

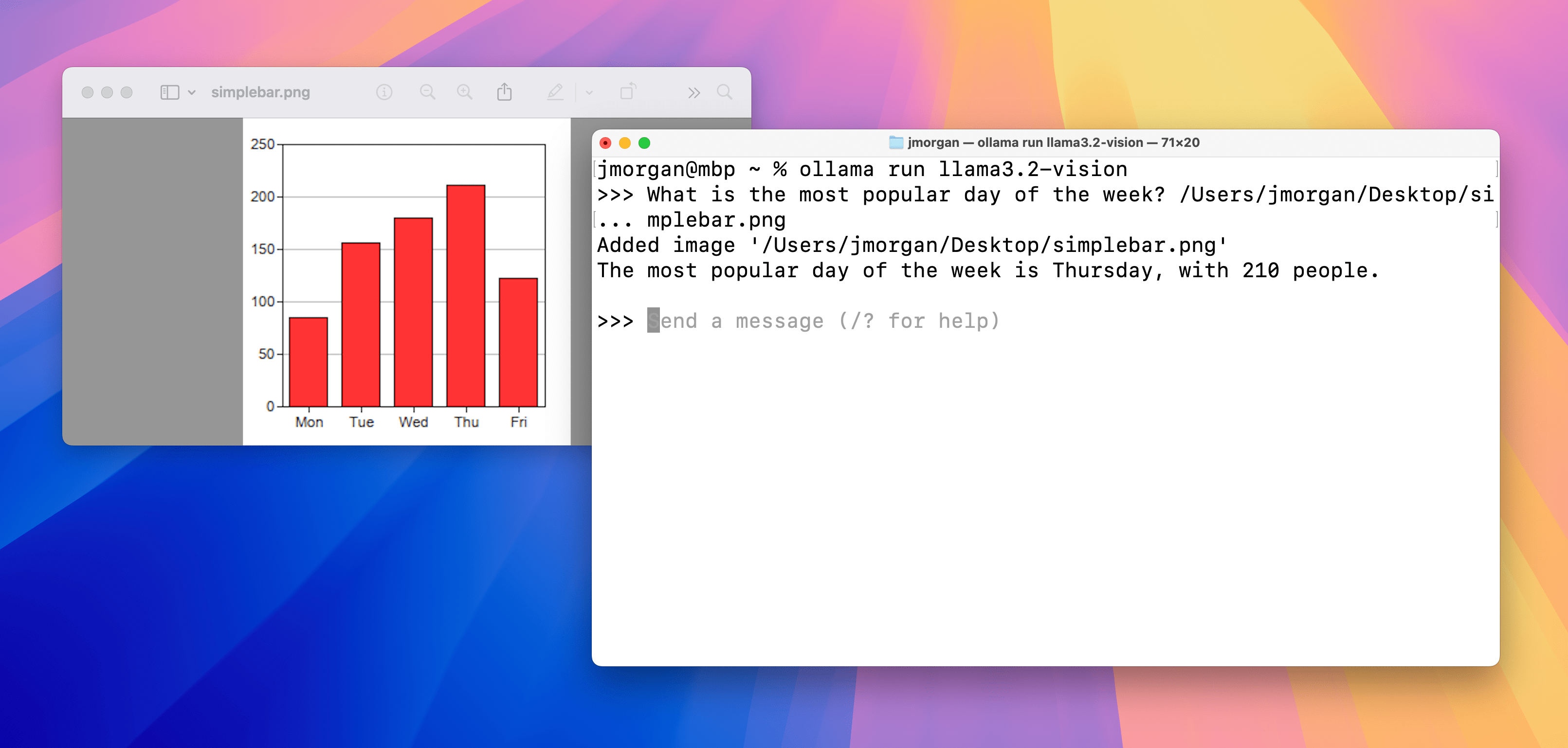
图表 & 表格
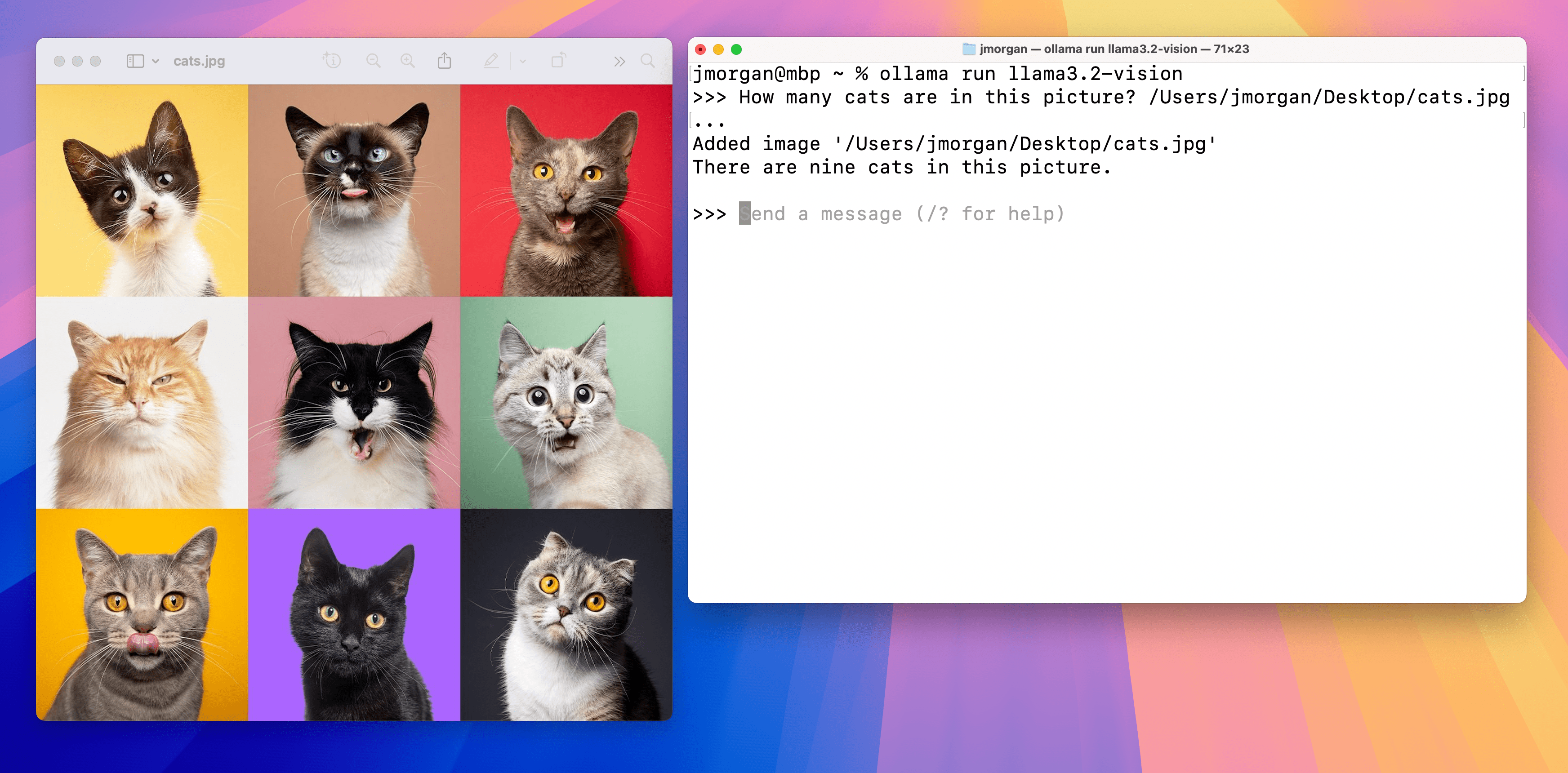
图像问答
用法
首先,拉取模型
ollama pull llama3.2-vision
Python 库
要将 Llama 3.2 Vision 与 Ollama Python 库 一起使用
import ollama
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': 'What is in this image?',
'images': ['image.jpg']
}]
)
print(response)
JavaScript 库
要将 Llama 3.2 Vision 与 Ollama JavaScript 库 一起使用
import ollama from 'ollama'
const response = await ollama.chat({
model: 'llama3.2-vision',
messages: [{
role: 'user',
content: 'What is in this image?',
images: ['image.jpg']
}]
})
console.log(response)
cURL
curl https://127.0.0.1:11434/api/chat -d '{
"model": "llama3.2-vision",
"messages": [
{
"role": "user",
"content": "what is in this image?",
"images": ["<base64-encoded image data>"]
}
]
}'
